在win10安装gpu版TensorFlow
安装cuda9.0
将以下路径进入环境变量PATH中
1
2
3
| C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64
|
安装TensorFlow
1
| pip install tf-nightly-gpu
|
安装完成后,检测下cuda是否可用
1
2
| $ python
$ import tensorflow as tf
|
假如显示cudart64_XX.dll失败,则卸载当前cuda,并下载对应版本号的cuda,若显示缺少cudnn,则继续下一步。
安装cudnn
下载cudnn并解压到cuda目录下
测试TensorFlow-gpu是否安装成功
进入python,执行以下代码
1
2
3
4
5
6
7
8
9
| import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print sess.run(c)
|
出现xxx则表明安装成功。
下载TensorFlow Object Detection API
作为当下深度学习的热门框架,TensorFlow提供了许多现成的深度网络结构,免去开发者构建底层网络的烦恼,大大降低了开发难度,这里我们使用的是Object Detection(对象检测模型)
下载TensorFlow models
下载完成后将tensorflow的models安装到计算机中。通过cd命令进入到d:/tensorflow/models/research 目录,执行
1
2
| python setup.py install
|
安装protobuf
下载protobuf
加入以下路径到环境变量PATH中
1
| D:\TensorFlow\protobuf-3.4.0\bin
|
添加环境变量proto_path
1
| D:\TensorFlow\protobuf-3.4.0\bin\protoc.exe
|
编译protobuf库
1
| protoc object_detection/protos/*.proto --python_out=.
|
创建PYTHONPATH变量,将models和slim加入其中
1
2
3
| d:/tensorflow/models/research
d:/tensorflow/models/research/slim
|
安装labelImg
labelImg用于在训练数据集图片中标注要识别的物体,并生成相关的xml文件
1.下载labelImg,解压到TensorFlow目录下
2.安装PyQt5
3.安装PyQt5_tools
4.安装lxml
5.pyrcc编译资源文件
进入labelImg文件夹,执行以下命令
1
| pyrcc5 -o resources.py resources.qrc
|
6.测试是否安装成功
弹出窗口,安装已成功。
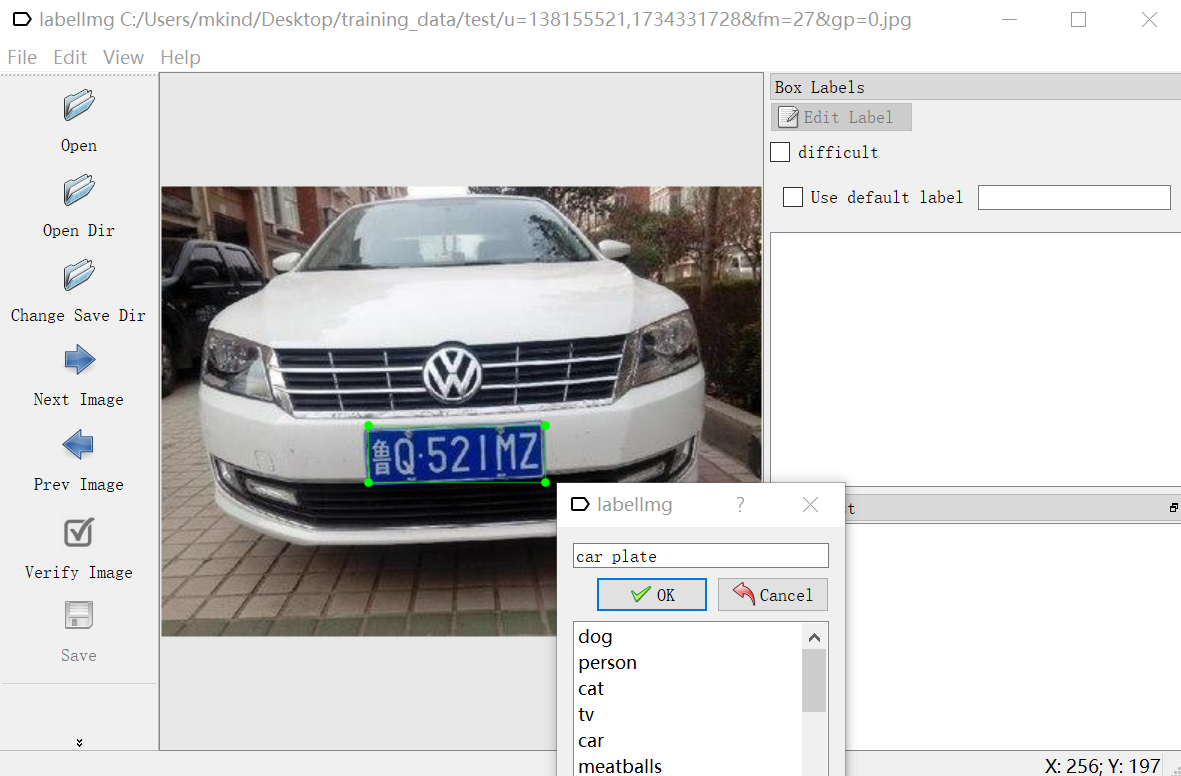
图像标注
xml转csv
下载raccoon_dataset,并解压到与object_detection同一级目录下。使用xml_to_csv.py,修改其中的image_path为训练集路径,运行该文件生成训练集数据csv
1
2
3
4
5
6
| def main():
# image_path = os.path.join(os.getcwd(), 'annotations')
image_path = r'C:\Users\mkind\Desktop\training_data\xml\train'
xml_df = xml_to_csv(image_path)
xml_df.to_csv('car_plate_train_labels.csv', index=None)
print('Successfully converted xml to csv.')
|
测试集同理:
1
2
3
4
5
6
| def main():
# image_path = os.path.join(os.getcwd(), 'annotations')
image_path = r'C:\Users\mkind\Desktop\training_data\xml\test'
xml_df = xml_to_csv(image_path)
xml_df.to_csv('car_plate_test_labels.csv', index=None)
print('Successfully converted xml to csv.')
|

csv转record
打开raccoon_dataset下的generate_tfrecord.py,这里需要做一些修改,首先要保证Object Detection导入成功,加入以下代码就可以导入上一级目录的的object detection
1
2
| import sys
sys.path.append('../')
|
修改33行左右的label,就是在标注训练集时所添加的label
1
2
3
4
5
6
|
def class_text_to_int(row_label):
if row_label == 'car plate':
return 1
else:
None
|
修改训练集图片路径
1
2
3
4
| def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = r'C:\Users\mkind\Desktop\training_data\test'
|
运行generate_tfrecord.py,此时csv将会被转为record
1
| D:\TensorFlow\raccoon_dataset>python generate_tfrecord.py --csv_input=car_plate_test_labels.csv --output_path=car_plate_test_labels.record
|
转换成功:

训练集也同样按照以上步骤生成car_plate_train_labels.record。
这样就得到了训练与测试所需要的car_plate_test_labels.record、car_plate_train_labels.record。
创建label_map.pbtxt
1
2
3
4
| item {
id: 1
name: 'car plate'
}
|
训练
下载预训练模型
ssd_mobilenet_v1_coco_11_06_2017.tar.gz
解压到object_detection目录下
修改ssd_mobilenet_v1_pets.config
打开object_detection\samples\configs下的ssd_mobilenet_v1_pets.config
修改如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| fine_tune_checkpoint: "D:/TensorFlow/models/research/object_detection/ssd_mobilenet_v1_coco_11_06_2017/model.ckpt"
train_input_reader: {
tf_record_input_reader {
input_path: "C:/Users/mkind/Desktop/training_data/car_plate_train_labels.record"
}
label_map_path: "C:/Users/mkind/Desktop/training_data/label_map.pbtxt"
}
eval_config: {
num_examples: 40
}
eval_input_reader: {
tf_record_input_reader {
input_path: "C:/Users/mkind/Desktop/training_data/car_plate_test_labels.record"
}
label_map_path: "C:/Users/mkind/Desktop/training_data/label_map.pbtxt"
shuffle: false
num_readers: 1
}
|
注意路径分隔符为”/“而不是”",否则会出现((unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escap
)的错误
开始训练
到目前为止,准备训练的文件就有
1
2
3
4
| ssd_mobilenet_v1_pets.config
label_map.pbtxt
car_plate_test_labels.record
car_plate_train_labels.record
|
进入d:/TensorFlow/models/research
运行
1
2
3
|
python object_detection/train.py --logtostderr --pipeline_config_path=C:/Users/mkind/Desktop/training_data/ssd_mobilenet_v1_pets.config --train_dir=D:\train_dir
|
pipeline_config_path:config文件路径
train_dir:存放训练生成文件的目标目录
生成pb
1
| python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path C:/Users/mkind/Desktop/training_data/ssd_mobilenet_v1_pets.config --trained_checkpoint_prefix d:/train_dir/model.ckpt-10028 --output_directory D:/train_dir/result
|
pipeline_config_path:config文件
trained_checkpoint_prefix:model.ckpt位置
output_directory:输出pb位置
可能出现的错误
TensorFlow Models:ImportError: No module named ‘deployment’
解决:加入环境变量
Check failed: stream->parent()->GetConvolveAlgorithms(&algorithms)
原因:cudnn版本与cuda不对应
解决:重新下载cudnn
OOM when allocating tensor with shape
原因:GPU内存不足,batch size太大。
解决:修改ssd_mobilenet_v1_pets.config中的batch size